

The ability to accurately predict leukemic relapse post-HSCT would improve outcomes by allowing pre-emptive therapeutic strategies. Recent studies have identified post-transplant T- and CD34 cell chimerism as predictors of relapse in patients, who had undergone HSCT for hematologic malignancies (Preuner et al, 2016; Lee et al, 2015). However, these studies assess relapse risk looking at only a single threshold of chimerism using standard regression analysis, which permits only limited consideration of other patient variables. As the result, the findings of these analysis are frequently not applicable to patients generally. Machine learning methods offer the possibility to capture nonlinear relationships and simultaneous interactions between multiple variables, thus better recapitulate the dynamics and nuances of the relapse process in different patients.
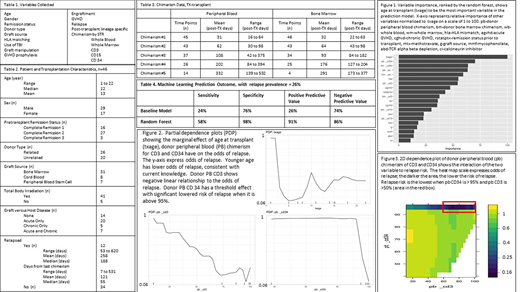
We use machine learning methods, specifically random forest classification (RF), to build a predictive model of post-transplant relapse and to analyze the data from a cohort of 46 pediatric patients, who received HSCT for acute lymphoblastic leukemia (ALL) and had serial lineage-specific chimerism testing post-transplant. Our model achieved 58 % sensitivity and 98% specificity at predicting relapses in cross validation compared to a baseline model (24% sensitivity, 76% specificity). Consistent with previous reports, our model implicates both peripheral blood (PB) donor CD34 and CD3 chimerism as important variables for relapse. More importantly, the RF showed how different variables interacted with each other, providing additional insights into how to best interpret post-transplant chimerism results. To our knowledge, this is the first study featuring RF machine learning methods in the clinical setting of relapse after HSCT.
We use a dataset of patients with ALL undergoing HSCT at Lucile Packard Children's Hospital from 2012 to 2018. Variables collected are summarized in Table 1. The analytical sensitivity of STR-based chimerism testing is 1%. Chimerism results on the same day of relapse were excluded from the analysis. The RF model is based on a set of 500 individual decision trees, each based on a bootstrapped sample of the patient data. A 5-fold cross-validation was used to test predictive skill, with 20% of patients excluded from each fold. We compared results with a Monte Carlo baseline model in which relapse status was repeatedly assigned randomly to each patient with a probability based on the prevalence of relapse in our cohort.
Patients, transplantation, and relapse characteristics are summarized in Table 2. Chimerism data are summarized in Table 3. The cross-validation results show a robust predictive skill of relapse within 2 years post-transplant. Our RF achieved 58% sensitivity and 98% specificity, greatly improving the predictive values from the base model (Table 4).
Variable importance, the ability of a variable to decrease the error of the prediction model, was calculated for all variables used in our RF (Figure 1). Our analysis shows that the age at the time of transplant has the highest importance, followed by PB donor CD34 chimerism. Bone marrow chimerism generally has lower importance suggesting PB monitoring only is adequate in the clinical setting.
We showcase the relationships of 1) age at transplant, 2) donor PB CD34, and 3) donor PB CD3 chimerism to the odds of relapse using a partial dependence plot. Younger patients relapse less often. Donor PB CD34 chimerism exhibits a threshold effect, in which the odds of relapse dramatically decreases when it is above 95% while donor PB CD3 chimerism has a more gradual linear profile (Figure 2). 2D dependence plot of donor PB CD34 and PB CD3 chimerism shows the interaction of the two variables (Figure 3) as continuous variables; relapse risk remaining low with even if donor PB CD3 chimerism is as low as 50% as long as donor PB CD34 chimerism is > 95%.
Our study shows that machine learning methods such as RF can be very useful at making accurate predictive model of post-HSCT complications that incorporates multiple variables, allowing for more granular differentiation between different patients. Such analyses can enable more effective deployment of risk-adapted, personalized treatment. By building hundreds of independent decision trees, the RF is also able provide useful insights to the interaction between different variables in a clinically relevant manner.
No relevant conflicts of interest to declare.

